Blog
You can’t do that online anymore!
Filtrer par :
Récents…
… in
English
… en français
Billets de blog récents
Notes récentes
Astuces récentes
Citations récentes
Rebuilding the site
I’m rebuilding the site and completing the transition to a pandoc based ikiwiki.
Notice something not working or a dead link? Get in touch! Thanks.
Thanks to the amazing work over fed.brid.gy by @snarfed.org@snarfed.org, this little website is now part of the fediverse!
This post is also a test.
Ces deux théories étaient séduisantes intellectuellement mais les recherches scientifiques remettent sérieusement en cause leur validité… force est de constater qu’il faudrait désormais cesser d’avoir recours à l’Effet Dunning-Kruger ou au concept de bulles de filtre (“filter bubbles”).
Restoring an HP Touchpad webOS tablet
Accepter les cookies et le traçage publicitaire, ou payer
« Il est difficile de dire la vérité, car il n’y en a qu’une, mais elle est vivante, et a par conséquent un visage changeant. »
Franz Kafka,
cité par Étienne Klein, Le goût du vrai (2020)
The EU General Data Protection Regulation explained by Americans
Twitter et le bistro
Blanche Gardin nous parle de Twitter, c’est très drôle et assez juste, et ça m’a rappelé ce billet à propos de liberté d’expression et droit à l’oubli.

Censure de la loi Avia
Le Conseil constitutionnel vient de rendre sa décision sur la loi visant à lutter contre les contenus haineux sur internet, adoptée par le Parlement sur proposition de Madame la députée Laetitia Avia.
Cette décision pose deux difficultés.
La première tient au fait que la censure est quasi-totale. On peine donc à déterminer ce qu’il en reste. La seconde tient à cette interrogation : comment un texte de loi peut-il en arriver là ? Le Conseil d’État s’était pourtant penché sur la question en 2019.
Données sur le net : tous suspects
Rebuilding the site
I’m rebuilding the site and completing the transition to a pandoc based ikiwiki.
Notice something not working or a dead link? Get in touch! Thanks.
Thanks to the amazing work over fed.brid.gy by @snarfed.org@snarfed.org, this little website is now part of the fediverse!
This post is also a test.
Restoring an HP Touchpad webOS tablet
The EU General Data Protection Regulation explained by Americans
Here some little known, yet awesome apps or tools that I use. Thanks to the people working on these (I’m glad to have met some of them, and they’re awesome too)!
 Transportr
Transportr
Transportr is an Android app to help you use public transports systems. It’s simply the best one I’ve seen, and it supports a lot of systems (city-wide like Berlin or Paris and even long-distance).
 Feedbin
Feedbin
Feedbin is an RSS web reader. It provides a pleasing reading experience and you can easily browse through items and share links. If you’re looking to host it yourself, have a look at the sources.
 ikiwiki
ikiwiki
ikiwiki powers this blog, hosted by branchable. If you like git and markdow, and editing your texts with your favourite text editor, this is for you.
 Known
Known
Known (formerly “idno”) is more “socially aware” than ikiwiki. It runs with PHP and it’s basically your easy-to-run indieweb space. If you use it with http://brid.gy you will enjoy a nice integration with twitter and other silos (see an example of my own).
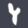 YunoHost
YunoHost
YunoHost is custom debian distribution aiming at making self-hosting easy. It provides a nice web interface for administration of your self-hosted server and for users of the web server. If you have basic linux administration skills, this will be very helpful.
 Pinboard
Pinboard
Pinboard a simple and efficient bookmarking app that also archives the content of marked pages (if you pay for it). Unfortunately, Pinboard is not released as free software. But you can export your bookmarks.
 Sharesome
Sharesome
Sharesome lets you easily share files on the web. It has a pleasant interface that works well on all devices I have tested so far. It’s also available as a web app. The neat feature is that you can choose where to host your data (for instance, with remotestorage; you can get an account at https://5apps.com).
 Terms of Service; Didn’t Read
Terms of Service; Didn’t Read
Some shameless self-promo with ToSDR, the app that tells you what happens to your rights online by rating and summarising Terms of service and privacy policies. You can also get it directly in your web browser or as a web app.
If you’re looking for a curated list of awesome web services that are free of charge and based on free software and open data, look no further than Jan’s Libre projects.
Understanding Technology
This morning, we are officially publishing the User Data Manifesto 2.0.
Today, most of users’ data are not stored on their computer’s hard drive any more, but rather online on a service provider’s server somewhere in a data center.
While most computing happened on local machines, in the late years a new kind of “computing“ has emerged in daily use. Marketers have called this “Cloud computing”—but do not mistake, as there is no cloud, it’s just some one else’s computer.

Most popular online services nowadays are gratis, but that does not mean that they come at any cost. Instead of paying with money, people are paying allegiance to service providers. In the land of “Minitel2.0”, Google and Facebook are like feudal lords of the Internet and we are their mere subjects. The exploitation of user data and of personally identifiable information is leading to numerous privacy invasion, some of which were only revealed thanks to Edward Snowden’s leak from the NSA.
|
If you’re looking to protect your privacy or if you want to know how your rights can be affected when using these online services, you usually don’t have many options but to look for adjusting increasingly complex privacy settings or you need to be a full time lawyer to read the lenghty terms of service.
The User Data Manifesto aims at defining the basic rights that users should have on their own data when using online services. Recognising these rights is an important first step towards a free society in the digital age, along with Free Software.
Indeed, users should have:
Control over user data access
User data should be under the ultimate control of the user. Users should be able to decide whom to grant direct access to their data and with which permissions and licenses such access should be granted.
Data generated or associated with user data (e.g. metadata) should also be made available to that user and put under their control just like the user data itself.
Knowledge of how user data is stored
When user data is uploaded to a specific service provider, users should be informed about the geographic location that specific service provider stores the data in, how long, in which jurisdiction that specific service provider operates and which laws apply.
This point is not relevant when users are able to store their own data on devices in their vicinity and under their direct control (e.g. servers) or when they rely on systems without centralised control (e.g. peer-to-peer).
Freedom to choose a platform
Users should always be able to extract their data from the service at any time without experiencing any vendor lock-in.
Read the full text of the manifesto here
I’m very happy that, with Frank and Jan, we are today announcing the release of version 2.0 of the manifesto during the ownCloud conf keynote.
Organisations and activists defending digital rights are joining in this effort to support online services that respect users’ rights. I am proud to be part of that effort and I hope it’s the start of a constructive debate and, hopefully, a humble contribution to our society.
I look forward to your feedback on the manifesto, which I view as a starting point rather than an end in itself.
Thanks to ownCloud, Inc for inviting me over to the ownCloud conf in Berlin.
Overview of FDN & La Quadrature’s challenge against Website Blocking
Sometimes, you want to get numbered paragraphs throughout a document.
I'm looking for a way to achieve this with pandoc, in a way that I can write once, and publish in several formats.
I added this in pandoc's LaTeX template:
$if(numberparagraphs)$
%% numerate paragraphs with a label
\newcounter{paranumero}
\newcommand{\para}[1]{%
\noindent\refstepcounter{paranumero}\llap{\small\bfseries\theparanumero\label{#1}.~}}
$endif$
That way, I can write
\para{shortId} A paragraph...
and later in the document, I can refer to that paragraph\vref{shortId}
That's good, but it only works in LaTeX. I'd like to write something similar in a Markdown document and be able to also produce HTML, or even ODT or OOXML.
I'll experiment a bit, but if you have ideas of your own... tell me :-)
TODO: allow to write \para without any value and assign it a
predictable \label... for instance the first letter of the first
five words of the paragraph.
Ces deux théories étaient séduisantes intellectuellement mais les recherches scientifiques remettent sérieusement en cause leur validité… force est de constater qu’il faudrait désormais cesser d’avoir recours à l’Effet Dunning-Kruger ou au concept de bulles de filtre (“filter bubbles”).
Accepter les cookies et le traçage publicitaire, ou payer
« Il est difficile de dire la vérité, car il n’y en a qu’une, mais elle est vivante, et a par conséquent un visage changeant. »
Franz Kafka,
cité par Étienne Klein, Le goût du vrai (2020)
Twitter et le bistro
Blanche Gardin nous parle de Twitter, c’est très drôle et assez juste, et ça m’a rappelé ce billet à propos de liberté d’expression et droit à l’oubli.
Censure de la loi Avia
Le Conseil constitutionnel vient de rendre sa décision sur la loi visant à lutter contre les contenus haineux sur internet, adoptée par le Parlement sur proposition de Madame la députée Laetitia Avia.
Cette décision pose deux difficultés.
La première tient au fait que la censure est quasi-totale. On peine donc à déterminer ce qu’il en reste. La seconde tient à cette interrogation : comment un texte de loi peut-il en arriver là ? Le Conseil d’État s’était pourtant penché sur la question en 2019.
Données sur le net : tous suspects
Hier, j'étais au loop avec Okhin pour refaire le chiffrement de mon serveur mail, que je viens de réinstaller (Kolab 3.4, Debian 8).
Voici quelques liens qui nous ont été utiles :
How to create a self-signed SSL Certificate
Attention cependant, en suivant ces instructions on crée un certificat avec le flag CA false alors que pour utiliser un certificat autosigné sur Android, il faut absolument que le flag CA soit true (voir ci-dessous).
Finalement, voici la commande qui m'a permis de faire le certificat, dans
/etc/ssl/private/:openssl req -x509 -new -key totosh.ampoliros.net.key -out totosh.ampoliros.net.csr -days 730Cette commande remplace l'étape 2. L'étape 4 n'est donc pas nécessaire semble-t-il.
Ensuite, je copie
totosh.ampoliros.net.csrvers/etc/ssl/certs/totosh.ampoliros.net.crtpuis je configure mes services pour utiliser ce certificat ainsi que la clé privée générée à l'étape 1.-
Utilisé pour configurer Apache2.
Exemples de configuration Postfix de Benjamin Sonntag
Sans oublier de générer
dh2048.pem:openssl dhparam -out /etc/ssl/private/dh2048.pem -outform PEM -2 2048-
Utilisé pour configurer Cyrus IMAPD.
Importer un certificat autosigné dans Android
Normalement, avec la commande openssl donnée plus haut, on génère un certificat autosigné acceptable pour Android.
On peut par exemple utiliser l'application CAdroid pour importer le certificat.
Si on est root sur l'Android, on peut aussi copier le certificat
directement dans le système en passant par adb. C'est la solution
que j'ai choisie.
Installing CAcert certificates on Android as 'system' credentials without lockscreen - instructions
(En passant: j'ai un bug sur CyanogenMod qui m'enmpêche pour le moment
de modifier les paramètres de sécurité. Je suis donc passé par adb
pour autoriser l'installation de sources autres que Google avec la
commande: adb shell settings put secure install_non_market_apps 1.)
Décompilation d’un logiciel : état des lieux
Article écrit pendant mon stage d’élève-avocat chez Derriennic Associés :
Dans un arrêt du 18 mars 2015, la Cour d’appel de Caen a retenu que l’acte de décompilation d’une partie de Skype n’était pas constitutif du délit de contrefaçon, relaxant ainsi l’associé d’une société de sécurité informatique française qui voulait développer un système d’échanges d’informations sécurisé et fiable, interopérable avec Skype.
Lire la suite… (lemondedudroit.fr) ou Télécharger la version PDF
French Data Network contre le Gouvernement, acte 2
Après le dépôt de la requête introductive d’instance contre le décret LPM, c’est au tour du décret organisant le blocage administratif du Web. Nous voici donc à l’acte 2 du contentieux engagé par French Data Network, la fédération de fournisseurs associatifs d’accès internet et La Quadrature du Net contre le gouvernement.
La première requête a été envoyée le 18 février. La deuxième requête est partie aujourd’hui. Les deux documents seront bientôt publiés. Je laisse le soin à Benjamin de le faire, probablement sur le blog de FDN.
Mise à jour: recours LPM, recours blocage administratif
Samedi dernier, j’ai pu présenter notre action lors de l’assemblée générale de FDN. Pour ceux que ça intéresse, voici les diapos. Ils contiennent notamment une chronologie du contexte entourant chacun des deux décrets que nous avons attaqué, ainsi qu’une revue de nos principaux arguments.
Voilà donc trois mois bien remplis qui viennent de passer, depuis la publication du décret LPM. À ce moment-là, on ne se doutait pas que le Gouvernement nous préparait une déferlante de textes attentatoires aux libertés individuelles et à la vie privée.
Il est vrai que le contexte malheureux de ce début d’année n’y est probablement pour rien…
L’actuel projet de loi relatif au renseignement rend donc notre action d’autant plus importante !
– Bah, la vérité, la vérité… Qui peut dire ce qui est vrai et ce qui ne l'est pas, commandant ! Pour nous, l'essentiel, ce n'est pas la vérité, c'est la justice, non ?
Pierre Lemaitre, Alex (2011)
Accepter les cookies et le traçage publicitaire, ou payer
The EU General Data Protection Regulation explained by Americans
Données sur le net : tous suspects
Understanding Technology
This morning, we are officially publishing the User Data Manifesto 2.0.
Today, most of users’ data are not stored on their computer’s hard drive any more, but rather online on a service provider’s server somewhere in a data center.
While most computing happened on local machines, in the late years a new kind of “computing“ has emerged in daily use. Marketers have called this “Cloud computing”—but do not mistake, as there is no cloud, it’s just some one else’s computer.
Most popular online services nowadays are gratis, but that does not mean that they come at any cost. Instead of paying with money, people are paying allegiance to service providers. In the land of “Minitel2.0”, Google and Facebook are like feudal lords of the Internet and we are their mere subjects. The exploitation of user data and of personally identifiable information is leading to numerous privacy invasion, some of which were only revealed thanks to Edward Snowden’s leak from the NSA.
|
|
If you’re looking to protect your privacy or if you want to know how your rights can be affected when using these online services, you usually don’t have many options but to look for adjusting increasingly complex privacy settings or you need to be a full time lawyer to read the lenghty terms of service.
The User Data Manifesto aims at defining the basic rights that users should have on their own data when using online services. Recognising these rights is an important first step towards a free society in the digital age, along with Free Software.
Indeed, users should have:
Control over user data access
User data should be under the ultimate control of the user. Users should be able to decide whom to grant direct access to their data and with which permissions and licenses such access should be granted.
Data generated or associated with user data (e.g. metadata) should also be made available to that user and put under their control just like the user data itself.
Knowledge of how user data is stored
When user data is uploaded to a specific service provider, users should be informed about the geographic location that specific service provider stores the data in, how long, in which jurisdiction that specific service provider operates and which laws apply.
This point is not relevant when users are able to store their own data on devices in their vicinity and under their direct control (e.g. servers) or when they rely on systems without centralised control (e.g. peer-to-peer).
Freedom to choose a platform
Users should always be able to extract their data from the service at any time without experiencing any vendor lock-in.
Read the full text of the manifesto here
I’m very happy that, with Frank and Jan, we are today announcing the release of version 2.0 of the manifesto during the ownCloud conf keynote.
Organisations and activists defending digital rights are joining in this effort to support online services that respect users’ rights. I am proud to be part of that effort and I hope it’s the start of a constructive debate and, hopefully, a humble contribution to our society.
I look forward to your feedback on the manifesto, which I view as a starting point rather than an end in itself.
Thanks to ownCloud, Inc for inviting me over to the ownCloud conf in Berlin.
Décompilation d’un logiciel : état des lieux
Article écrit pendant mon stage d’élève-avocat chez Derriennic Associés :
Dans un arrêt du 18 mars 2015, la Cour d’appel de Caen a retenu que l’acte de décompilation d’une partie de Skype n’était pas constitutif du délit de contrefaçon, relaxant ainsi l’associé d’une société de sécurité informatique française qui voulait développer un système d’échanges d’informations sécurisé et fiable, interopérable avec Skype.
Lire la suite… (lemondedudroit.fr) ou Télécharger la version PDF
Overview of FDN & La Quadrature’s challenge against Website Blocking
Overview of FDN & La Quadrature’s challenge against Data Retention
Last month, French Data Network and La Quadrature du Net filed a lawsuit to the Conseil d’État, one of the supreme courts, against the French government. Our objective is simple: we want to take down French data retention laws.
Who?
the French Data Network (FDN), the oldest French internet access provider, and a nonprofit organisation promoting the Internet and spreading knowledge on how it works.
the Fédération FDN, a federation of ISP very much like FDN (FDN is one of the founding members of the Fédération), created to spread and distribute efforts accross geographical locations to serve the same goal.
La Quadrature du Net, an organisation of activists (which used to be an unorganisation ;-)) defending our rights in the digital age. Maybe you know them for their successful campaigns against ACTA.
How?
On December 24, the government issued a décret, an order by the executive branch to enable the application of the law (issued by the Parliament). Décrets can be challenged in court, directly to the Conseil d’État, until two months after they are published. This is the procedure we’re in.
Formally, our target is a décret of the 2013 law setting the strategy for military operations and prerogatives for the near future (the “LPM” law). Specifically, article 20 of this law set new ways for the state to access data retained by telcos and internet ISPs.
For us, this was just a legal opportunity to seize in order to bring our arguments in front of a judge, against the concept of general data retention, i.e. keeping metadata and records on communications of the whole population.
In the aftermath of the European Union Court of Justice’s landmark decision in Digital Rights Ireland (April 8, 2014; C‑293/12 & C‑594/12), data retention laws in Europe are being cancelled, almost automatically, one by one (lately, in the Netherlands, see the preliminary injunction by the Hague court, March 11, 2015). Almost automatically indeed, because national judges, in matter of European Union law, have to apply EU principles and case law directly.
So this is what we’re trying to do in France, albeit one difference. Unlike other data retention laws in Europe, French laws predate the 2006 EU data retention directive; so our task seems a bit more difficult.
What?
Anyway, here comes an overview of our main arguments:
- the décret tries to fix the law; because the law did not define correctly its own scope (the definition of the type of data subject to the law). But that’s something the government is not supposed to do! The scope of the law is a legislative power prerogative, not the executive’s.
- the décret had to organise the administrative control defined in the law, but the décret doesn’t do it. Thus, the government did not fullfil the obligations the law created.
And, of course, the main argument (part 4.1 of our legal writing):
- This is a matter of European Union law. As the 2002 directive (so called ePrivacy directive) says in its article 15, measures of data retention must be made according to EU law principles.
- Thus, the EUCJ Digital Rights Ireland decision is directly applicable to French laws on data retention.
- As a consequence, the judge must realise that data retention, as set in French law, is clearly against our fundamental rights to free speech and to the respect of private life! The government cannot legally mandate telcos and internet ISPs to keep metadata and records on the communications of the whole population (and for a whole year at least)!
If you’re interested, you can read the whole thing (in French).
What next?
I’ll keep you posted on the blog about the procedure. It should take at minimum a year, if nothing unexpected happens (but it can be significantly longer depending on prejudicial and accessory procedures…).
But as you may know, the government is currently trying to pass new law giving extremely broad powers to the state with regard to surveillance measures, including new ways to access our communications and our data, all of this without effective judicial oversight.
Our legal challenge has thus taken a new level, against the French surveillance state.
Related: La Quadrature’s press release
French Data Network contre le Gouvernement, acte 2
Après le dépôt de la requête introductive d’instance contre le décret LPM, c’est au tour du décret organisant le blocage administratif du Web. Nous voici donc à l’acte 2 du contentieux engagé par French Data Network, la fédération de fournisseurs associatifs d’accès internet et La Quadrature du Net contre le gouvernement.
La première requête a été envoyée le 18 février. La deuxième requête est partie aujourd’hui. Les deux documents seront bientôt publiés. Je laisse le soin à Benjamin de le faire, probablement sur le blog de FDN.
Mise à jour: recours LPM, recours blocage administratif
Samedi dernier, j’ai pu présenter notre action lors de l’assemblée générale de FDN. Pour ceux que ça intéresse, voici les diapos. Ils contiennent notamment une chronologie du contexte entourant chacun des deux décrets que nous avons attaqué, ainsi qu’une revue de nos principaux arguments.
Voilà donc trois mois bien remplis qui viennent de passer, depuis la publication du décret LPM. À ce moment-là, on ne se doutait pas que le Gouvernement nous préparait une déferlante de textes attentatoires aux libertés individuelles et à la vie privée.
Il est vrai que le contexte malheureux de ce début d’année n’y est probablement pour rien…
L’actuel projet de loi relatif au renseignement rend donc notre action d’autant plus importante !
Starting against Data Retention in France
If you’ve been wondering why I haven’t blogged lately, or why I haven’t replied to your email yet, it’s because I have been quite busy so far for this new year.
Besides starting at a law firm in Paris for 6 month (the last internship required by the Bar school, at last!) I also joined French Data Network, La Quadrature du Net and the Federation of Do-It-Yourself Internet access/service providers in a lawsuit against the French government on Data Retention.
This is just the beginning, but I’m quite thrilled about it already.
If you read French, Benjamin Bayart will give you a good idea of what it’s about on FDN’s blog.
/me, now catching up on email of the week.
Patent Facts
Some facts and statistics about patents (with a focus on software and information technology). I will update this post from time to time, so subscribe to the feed to get notified! Please suggest other noteworthy facts in the comments.
the number of patent lawsuits filed each year in the US has tripled.
source: New York Times
years: 1990-2010
“Internet software patents” are litigated eight times as often as other patents.
source: Allison, Standford [404] in 2012 Stan. Tech. L. Rev. 3 SSRN
years: 1998-2009
In Germany, patents covering software and telecoms are invalidated by courts in 88.11% of cases. For all patents, the main ground for invalidations by the German Federal Patent Court is lack of patentability in 75% of the cases.
source: Bardehle [pdf]
years: 2010-2013
In the US, patents challenged on the basis of the US Supreme Court Alice v. CLS Bank decision are invalidated by Federal Circuit courts in 91.9% of cases (66.5% for all courts). (Also ses Deb Nicholson’s talk)
source: Japser L. Tran, Univ. of Minnesota
years: 2013-2016
Apple and Google spend more on patent litigation and patent purchases than on research and development.
source: New York Times
year: 2011
IBM abandons around 40% of their US patents in the first three years.
source: patentlyo
year: 2012
IBM has been granted most US patents for [more than] 20 years in a row
source: bloomberg
year: 2013
More than 1000 software patents are granted each year by the EPO or EPC states.
source: European Commission
years: 1978-2002
More than 20 000 patent applications on “digital communications”, “IT methods” and “computer technology” are filed each year at the EPO.
source: European Patent Office
year: 2013
88% of the patents held by “patent assertion entities” (a.k.a. “patent trolls”) in the US are information and communication technology patents, with more than 75% software-related.
source: US Federal Trade Commission (FTC) pdf
years: 2009-2014
The following assertions rely on surveys or do not have reliable sources or data. If you have some idea of a better source for these facts, please get in touch.
52% of companies purchase patents to secure freedom to operate
source: IAM
year: 2015
Between 40% and 90% of all patents issued are never used or licensed by their owners.
source: The Economist
year: ???
Good articles and other sources on patent facts
Journalism
- Duhigg, Charles, and Steve Lohr. “In Technology Wars, Using the Patent as a Sword.” The New York Times, October 7, 2012, sec. Technology. http://www.nytimes.com/2012/10/08/technology/patent-wars-among-tech-giants-can-stifle-competition.html. I summarised this article on my old blog
Official statistics
- WIPO Statistics: http://www.wipo.int/ipstats/en/
- EPO reports and statistics: http://www.epo.org/about-us/annual-reports-statistics.html
- USPTO statistics: http://www.uspto.gov/about/stats/index.jsp
Not patent facts
Unfortunately, a lot of debates on patents do not rely on facts, especially debates on patents applied to information technology. Instead, we are witnessing what Mark Lemley has described as “Faith-Based Intellectual Property”. Here’s a list of things which are not facts about patents but which are often asserted.
“companies invest heavily in software research and development in the United States because new inventions, implemented through software, can be protected by patents”. Yet, the article that makes this assertion offers absolutely no evidence that the eligibility of software as patent subject matter has specifically contributed significantly to US growth in software research and development.
(I would also note that the conclusion in the executive summary is legally incorrect: the promotion of progress in the useful arts is not a “constitutional imperative”; under the US constitution, Congress “shall have the power to“ promote the progress in the useful arts, but this is not an imperative.)
source: David J. Kappos (former USPTO president) and Aaron Cooper, At the core of America’ s competitive edge: why software - implemented inventions are — and must remain — patent eligible [pdf], Aug 26, 2015
The EUCJ has just published another decision regarding data protection that got me puzzled (but I’m not the only one!).
This one is primarily concerned with the interpretation of exceptions to the 1995 directive, but it also has interesting things to say regarding the infamous so-called right to be forgotten decision where legitimate interests in personal data processing were involved.
The facts are simple: someone puts a camera to monitor the entrance of his house. One day, people break in, but they are later identified thanks to the camera. Then, these suspects challenge the legality of the camera system on the grounds that they were not notified of the processing of their personal data.
Article 3 of the 1995 directive provides:
2 This Directive shall not apply to the processing of personal data: […]
– by a natural person in the course of a purely personal or household activity.’
But for the Court, (emphasis is mine)
33 To the extent that video surveillance such as that at issue in the main proceedings covers, even partially, a public space and is accordingly directed outwards from the private setting of the person processing the data in that manner, it cannot be regarded as an activity which is a purely ‘personal or household’ activity
This is a strange reasoning in my opinion, as it seems to make no distinction between purely personal activities and purely household activities–they are now combined under the criteria of the “private setting.”
So here’s how this applies to us: thanks to Neil, we already have a solution!
How does this relate to the so-called right to be forgotten?
The Court notes that:
34 At the same time, the application of Directive 95/46 makes it possible, where appropriate, to take into account — in accordance, in particular, with Articles 7(f), 11(2), and 13(1)(d) and (g) of that directive — legitimate interests pursued by the controller, such as the protection of the property, health and life of his family and himself, as in the case in the main proceedings.
I wish the Court followed the same approach in the so-called Right to be forgotten decision. But instead, the legitimate interest of the public to access published information has not been taken into account.
Some comments on the EU’s draft Privacy Icons
The European Union is currently reviewing the regulatory framework of personal data protection. In the current draft, a standardised icon set would be mandatory in some circumstances.
I’m not convinced this is the best implementation, and there’s even one icon in the set that I’m really concerned about: “Encryption”. This proposal could undermine years of activism in favour of better encryption for users.
As I’ve been working on Terms of Service; Didn’t Read for a couple of years now, I have some experience and idea about how this sort of things might work and how it compares to existing projects, especially in the fields of “Privacy Icons” where several projects coexist and keep raising much attention (including, it seems, from European legislators).
First, some context for those who haven’t followed (feel free to skip to the second part if you’ve followed personal data regulations updates in the EU). In January 2012, the European Commission announced a plan to revise data protection laws in the European Union with a draft regulation. Currently, most of the European Union’s laws on the protection of personal data come from a 1995 European Union directive. (Unlike a directive, a EU regulation is law that applies EU-wide without the need for each state to make their own internal legal implementation.)
So, this is going to be 20 years old soon. It’s quite extraordinary that even now, the directive does not seem too far off. The intentions are good and it’s a great thing that legislators foresaw the need to enhance people’s privacy back then (France and Germany already had a law for that by the end of the 1970s). But today, all this is in the middle of a huge battle.
After several steps through the European Union’s lawmaking process, the regulation is now in a consolidated draft.
I want to focus on the draft article 13a (in Chapter Ⅲ, Section 1: Transparency and modalities) which provides:
Where personal data relating to a data subject are collected, the controller shall provide the data subject with the following particulars before providing information pursuant to Article 14:
- whether personal data are collected beyond the minimum necessary for each specific purpose of the processing;
- whether personal data are retained beyond the minimum necessary for each specific purpose of the processing;
- whether personal data are processed for purposes other than the purposes for which they were collected;
- whether personal data are disseminated to commercial third parties;
- whether personal data are sold or rented out;
- whether personal data are retained in encrypted form.
The particulars referred to in paragraph 1 shall be presented pursuant to Annex X in an aligned tabular format, using text and symbols, in the following three columns:
- the first column depicts graphical forms symbolising those particulars;
- the second column contains essential information describing those particulars;
- the third column depicts graphical forms indicating whether a specific particular is met.
The information referred to in paragraphs 1 and 2 shall be presented in an easily visible and clearly legible way and shall appear in a language easily understood by the consumers of the Member States to whom the information is provided. Where the particulars are presented electronically, they shall be machine readable.
Additional particulars shall not be provided. Detailed explanations or further remarks regarding the particulars referred to in paragraph 1 may be provided together with the other information requirements pursuant to Article 14.
The Commission shall be empowered to adopt, after requesting an opinion of the European Data Protection Board, delegated acts in accordance with Article 86 for the purpose of further specifying the particulars referred to in paragraph 1 and their presentation as referred to in paragraph 2 and in Annex 1.
Why the “Encryption” icon is a bad idea?
TL;DR Storing sensitive data in data centers without encrypting them first is just negligence and should not be allowed. There’s no need for an icon that probably a large majority of users will not really understand.
In the draft proposal, when personal data is collected, the person who’s subject of that data should get information in the form of a standardised icon. One of the icons proposed is about encryption:

If the data is stored encrypted, then the data controller can display a huge green mark next to the icon. All is fine!
Except that it’s not. I can really see how this could get very, very confusing. It is very easy to claim that something “is encrypted” and that thus, everything’s good. I’ve heard this argument several times from Google employees: Google stores the data in encrypted forms, so don’t worry. But still, when Google access the data to process it, it is decrypted by them.
Let’s put this in context.
Following Edward Snowden’s revelations, it is very clear that encryption is one part of the solution against the intrusion in our lives that the NSA and other State agencies in the world are pursuing. Thus, it is crucial that users understand that there are ways to protect their communications against the intrusion of the State, and also from companies or criminals. This is why initiatives such as Cryptoparties and Privacy Cafés, where people help each other understand and use encryption techniques, are so important!
But encryption does not always mean the same thing in all contexts. It requires basic technological understanding to grasp when encryption is simply a security good practice against criminals, and when encryption is actually a much more powerful tool.
For instance, when I send sensitive information over the web (like a financial transaction, or like my user nick and password), it is very important that the connection is encrypted (e.g. using HTTPS); otherwise, it would not be difficult to intercept that sensitive information. Enabling encryption for that kind of stuff should simply be mandatory.
It’s a good idea to impose security obligations over storing personal data. But I fail to see how showing an icon to users about storing data in encrypted form will do any good. Worse, it might even confuse people about what encryption really means in which context, thus making it even harder to explain why encryption is important and why tools such as GnuPG should be improved in usability.
Is this standardised icon set really good anyway?
Raising awareness about privacy rights online is important. This is what I have been doing with Terms of Service; Didn’t Read for about two years now. I’ve seen several variations of the Privacy Icons idea, and this implementation as suggested by the EU draft regulation shows that getting it right is not easy.
The consolidated draft has an annex showing how the icons could be:

Depending on whether that’s the case, the data controller would have to display a green or a red mark next to this icon:

In ToS;DR, we also use this approach: for each point, there’s an iconic indication whether this is a good or a bad thing. Only, we allow for more variations:


But the major problem that I have with “Privacy Icons” is that they are too difficult to grasp. If you actually remove the text aside the icon itself, you realise that the icon itself is far from self-explanatory. This gets even more complex with the number of icons you add.
These icons are not universally understood. Here’s how the same concept is rendered differently by different Privacy icons sets:




Compare these with how a similar point would be addressed in ToS;DR:

which can be expanded with a plain-English paragraph and links to contextualise if the user wants more information:

There’s probably a way somewhere to learn from these different approaches and make an implementation that gets it right for users.
The EU already made such a thing possible with the energy efficiency labels. (They actually were a source of inspiration for ToS;DR classes.)
Let’s hope the next proposal gets it right with an icon system that is easier to understand and which gets rid of the confusing bits.
This is my first post.
I’ve been thinking about using ikiwiki for some time now. I don’t exactly know what I’ll do here, but I suspect I’m moving away from wordpress-powered http://blog.hugoroy.eu. The main reason is that I’m fed up of using the wordpress admin interface when all I want is to publish something I’ve written on my machine.
And git history.
I know I haven’t started writing yet, I’m already worried about technical issues. How can I handle writing in different languages here? I’ve seen the po plugin but it requires me to set a “Master language” for the whole system. Rather, I want to be able to set different master languages for each post.1 Because sometimes I start writing in French, some other times I start writing in English. Most of the time I don’t translate myselft. So translation isn’t really what I’m looking for.
If you’ve got any suggestion on how to solve this, you’re very welcome. Until then, I’ll just stick to tagging.
New defensive publication from ownCloud: file syncing encryption
How to produce defensive publications
Right to be forgotten — When the EUCJ forgot our freedom of expression
It’s been a few months now since the controversial EUCJ Google_Spain_v._González_(C-131/12) decision has been published. And I’m too busy, lagging behind: my draft (in French) on why I disagree a lot with this decision is still in the making. But it will eventually come. Meanwhile I got some interesting discussions, for instance with Neil Brown. I’m still waiting for Neil to set up is Known profile online somewhere so we can copy/paste our discussion there. Just now, Reuben Binns sent me a paper pointing out that, yes, the EUCJ decision overlooked the balance needed to protect our right to freedom of expression. By the way, Reuben has also written an interesting piece on how Wikipedia deals with person’s subjective rights – I think you should read it because I think Wikipedia is a very good illustration on how to do this right, and thus also an incredibly strong illustration on how the EUCJ’s so called “right to be forgotten” (RTBF for short) is wrong.
So, roughly and quickly, I’d like to point out a few flaws that I think are very worrying considering the wider context; namely, the European Union Court of Justice getting more powerful as a court dealing with fundamental rights (in addition to the European Court of Human Rights).
What does privacy mean anyway?
You may disagree but I think there’s no such thing as a personal, subjective right to “privacy”. A right to privacy is not the same thing in my opinion as a right to the “respect of your private life”. There is an important distinction to make. Maybe.
Privacy is an ecological thing as Moglen says, it’s not an individual thing. Privacy is often understood only in a given context: a technological context and a social as well as cultural context. We have different privacy expectations and understanding depending on who we communicate with, what we communicate about, where we communicate, by which means we communicate and based on the cultural background of the communicating parties. Note that “communicate” needs to be understood broadly and may not be the right word.
Privacy and the right to the respect of private life are intertwined, but not the same thing.
One of the most interesting researchers working on explaining privacy is danah boyd. She lately published a piece: What Is Privacy? (You should read the entire piece, it’s not long) in which she wrote:
The notion of private is also a social convention, but privacy isn’t a state of a particular set of data. It’s a practice and a process, an idealized state of being, to be actively negotiated in an effort to have agency.
[…]
While learning to read social contexts is hard, it’s especially hard online, where the contexts seem to be constantly destabilized by new technological interventions. As such, context becomes visible and significant in the effort to achieve privacy. Achieving privacy requires a whole slew of skills, not just in the technological sense, but in the social sense. Knowing how to read people, how to navigate interpersonal conflict, how to make trust stick. This is far more complex than people realize, and yet we do this every day in our efforts to control the social situations around us.
The core of the point is, privacy is not an individual’s subjective legal right. It’s a social and fragile, but needed social process. And we should wary of courts or governments intrusions into this social process.
In the EUCJ’s RTBF decision, the court does not give enough weight to the right of the public to access lawfully published information that can be of public interest. This is very worrisome because that right is substantially a consequence of our right to free speech.
The rationale, however, of the EUCJ analysis is unclear. To make their arguments justified by fundamental rights, the EUCJ takes article 7 of the EU Charter. This article is not a right to privacy, otherwise it would say just that: “a right to privacy.” Instead, it is a right to the “respect for private and family life” and that’s not the same thing.
On the one hand, the right to respect for private life is well established as a person’s subjective right. For instance, in France it used to be under general tort law (art. 1382) but then has taken its own stance in article 9 of the code civil and under the Declaration of human rights of 1789.
One important condition of such a right in a civil context is that there is a need to demonstrate préjudice, i.e. harm has been done to that persons’ in way of infringing their private life.
On the other hand, as already pointed out, privacy is a process. And as you know if you’ve read [the ECJ decision][c131-12], there’s no such need to demonstrate prejudice in order for the RTBF to apply.
The legal basis thus is not clear. Is this new so called “right to be forgotten” based on the right for the respect of private life (in this case it needs to be demonstrated that there is prejudice) or is it based on another part of the EU Charter, the one that recognises personal data protection? Well, if it’s the latter, then I think we should question the balance that the ECJ strikes with the RTBF. Should the RTBF be that powerful against the freedom to access lawful information that has not been demonstrated to cause any harm?
The EUCJ new “general rule” harms freedom of expression
The personal data protection directive says in article 7:
’Member States shall provide that personal data may be processed only if:
…
- processing is necessary for the purposes of the legitimate interests pursued by the controller or by the third party or parties to whom the data are disclosed, except where such interests are overridden by the interests [or] fundamental rights and freedoms of the data subject which require protection under Article 1(1).’
In the case where the service in question is accessible and used by a large majority of the population, it means that we are talking about the legitimate interests of the public. Surely, the right to access lawfully published information is a priori a legitimate interest of the public. Otherwise, what good is a right to freedom of expression if nobody else has the right to hear you and that someone can block access to your article when they feel like?
Now, let’s have another read at the article above (article 7). It is clear that the general rule is that processing of personal data is allowed when the right of the public to freedom of expression is at stake, except where the data subject’s fundamental rights should override them.
But as already pointed out, there is a confusion between fundamental rights and thus the whole analysis on balance breaks, at the detriment of the public’s right to access lawfully published information.
In the decision, the Court indeed invents a new “general rule”:
The rights to privacy of the data subject override “as a rule, not only the economic interest of the operator of the search engine but also the interest of the general public in finding that information upon a search relating to the data subject’s name.” (¶ 97)
It is clear now that there’s a problem. The rule and the exception have been exchanged.
Interesting fact: I just learned that the Spanish plaintiff, M. González, is a lawyer… This whole case and the decision to me, is an illustration of what goes wrong when we try to solve problems that should be best solved freely with our social processes. Solving privacy with this kind of ruling is doing us no favour.
The real privacy issues for us today come from massive surveillance by the NSA and other mass-surveillance State agencies aroudn the world. They also come from surveillance operated by companies.
Search engines giving access to lawfully published information is not the real privacy issue! The RTBF is the wrong fight, and it’s actually wasting our time; time that should be better spent fighting the real issues of massive surveillance which makes much more harm to our right to have a private life outside the reach of the State’s agents.
Finally, the ultimate irony of the decision is that Google and the like are the ones who have to apply individual’s requests to be deleted from search engines results relating to their names. Thus, giving the role of defining privacy to… Google. Well done for the rule of law.
We should demand that the European commission does not to pursue this RTBF nonsense, but instead focuses on the real issues affecting our privacy and our autonomy.
C’est aujourd’hui que paraît le roman de Suzanne, Meurtre à Sciences Po ! Je ne peux que vous inviter à aller le lire, car il est très divertissant et qu’il dépeint avec un humour pointé de sarcasme, les individualités parfois originales qu’on trouve rue Saint-Guillaume ! Évidemment comme son titre l’indique, il s’agit d’un roman policier. Vous me direz si on reconnaît l’influence d’Agatha Christie 😉

Et non, ce n’est pas moi sur la gauche, mais Maxime ! Je suis sur la droite mais il faut croire que je gâchais toute l’harmonie visuelle de la photographie ☺
Why I want to update the User Data Manifesto
Rebuilding the site
I’m rebuilding the site and completing the transition to a pandoc based ikiwiki.
Notice something not working or a dead link? Get in touch! Thanks.
Thanks to the amazing work over fed.brid.gy by @snarfed.org@snarfed.org, this little website is now part of the fediverse!
This post is also a test.
Ces deux théories étaient séduisantes intellectuellement mais les recherches scientifiques remettent sérieusement en cause leur validité… force est de constater qu’il faudrait désormais cesser d’avoir recours à l’Effet Dunning-Kruger ou au concept de bulles de filtre (“filter bubbles”).
Twitter et le bistro
Blanche Gardin nous parle de Twitter, c’est très drôle et assez juste, et ça m’a rappelé ce billet à propos de liberté d’expression et droit à l’oubli.
Censure de la loi Avia
Le Conseil constitutionnel vient de rendre sa décision sur la loi visant à lutter contre les contenus haineux sur internet, adoptée par le Parlement sur proposition de Madame la députée Laetitia Avia.
Cette décision pose deux difficultés.
La première tient au fait que la censure est quasi-totale. On peine donc à déterminer ce qu’il en reste. La seconde tient à cette interrogation : comment un texte de loi peut-il en arriver là ? Le Conseil d’État s’était pourtant penché sur la question en 2019.
I've had some problems with the ?timeline lately. I'm trying to see if there's a way to "reboot" it and get clean of the bits that should have been left out… This will probably flood the RSS a bit, sorry for the inconvenience!
Mozilla is currently promoting the new Firefox 29 (Go get it!). Now, they're asking us on Twitter: What do you want for the Web? So I clicked on their link and here's what I got.
 |
I haven't been able to play YouTube videos for weeks now. Sometimes, it works though. I have no idea what's going on…
Dear Mozilla, next time you publish a video on your website, I don't want Flash and I don't want YouTube. I want HTML5 video (in an open standard format, i.e. free of patent restrictions) and I don't want you to promote a platform with crappy terms of service.
I was reading an article by Lorrie Cranor in the MIT Technology Review on how it’s difficult even for her to protect her privacy online.
I appreciate Lorrie Cranor’s work on privacy at Carnegie Mellon University. I have extensively cited her study of the length of privacy policies when I introduced ToS;DR.
However in this article, I was disappointed to see Ghostery mentioned. Ghostery is an browser extension supposed to help users against tracking and surveillance on the web. The main problem is that Ghostery is not released as Free Software[^akaos]
[^akaos]: a.k.a Open Source. Both these terms designate the same set of programs.
Earlier on Twitter I quickly posted my frustration about this. People who promote web privacy should stop promoting Ghostery, as it’s proprietary. What’s their business model exactly? ;-)
In my earlier tweet I wrongly stated that the source code was not disclosed; but that’s not accurate. There is some code disclosed (I suppose it’s entirely readable and not obfuscated nor minified). But as you’ll notice, the license is “All rights reserved” so, basically, users have no rights.
Ghostery has been playing on the ambiguity for too long. This hypocrisy must stop. See these tweets from years ago…
@accessjames @phisab We are currently working on making it open source, it's an ongoing project. Ghostery blocks, no need for opting out.
— Ghostery (@Ghostery) 14 Janvier 2013this is good news :) RT @Ghostery: Currently, you can access Ghostery's code if you unpack the ext. We are still looking to open source, too
— Jeekajoo (@jeekajoo) May 28, 2013It seems Secret is the new thing. So I had a look at their terms of service. Here are some extracts:
However, unless we expressly state otherwise, your right to use the Service does not include (i) publicly performing or publicly displaying the Service,
That's funny, because it seems to imply that taking a screenshot of a secret and tweeting it is forbidden (although the Secret co-founder uses them in his post explaining how it works technically.)
When you post, link or otherwise make available content to the Service, you grant us a nonexclusive, royalty-free, perpetual, irrevocable and fully sublicensable right to use, reproduce, modify, adapt, publish, translate, create derivative works from, distribute, perform and display such content throughout the world in any manner or media, on or off the App.
This got to be the most extreme copyright license in Terms of Service that I have ever seen.
Basically, it's as if you did not exist as an author. Which is fine because it's supposed to be a secret. But in the process, Secret wants all the rights for themselves (and their future business partners I assume).
(I'm not sure that most Secret messages would pass the originality threshold required for copyright and authors' right protection anyway.)
Modification to the service
Secret reserves the right in its sole discretion to review, improve, modify or discontinue, temporarily or permanently, the Service and/or any features, information, materials or content on the Service with or without notice to you.
Suspension/Termination
Secret may suspend and/or terminate your rights with respect to the Service for any reason or for no reason at all and with or without notice at Secret’s sole discretion.
Governing Law; Arbitration
PLEASE READ THE FOLLOWING PARAGRAPHS CAREFULLY BECAUSE THEY REQUIRE YOU TO ARBITRATE DISPUTES WITH SECRET AND LIMIT THE MANNER IN WHICH YOU CAN SEEK RELIEF FROM SECRET.
[…]
If settlement is not reached within 60 days after service of a written demand for mediation, any unresolved controversy or claim will be resolved by arbitration in accordance with the rules of the American Arbitration Association before a single arbitrator in San Francisco, California.
Legal Compliance
You represent and warrant that: (i) you are not located in a country that is subject to a U.S. Government embargo, or that has been designated by the U.S. Government as a “terrorist supporting” country; and (ii) you are not listed on any U.S. Government list of prohibited or restricted parties.
That's funny. I guess I don't know if I'm on a US government list of restricted parties!
Oh, and here's the Privacy policy.
In case you thought you were “anonymous” when using Secret, think again:
We may share information about you as follows or as otherwise described in this privacy policy:
- In response to a request for information if we believe disclosure is in accordance with any applicable law, regulation or legal process, or as otherwise required by any applicable law, rule or regulation;
Wall Street Journal: The encryption flaw that punctured the heart of the Internet this week underscores a weakness in Internet security: A good chunk of it is managed by four European coders and a former military consultant in Maryland.
To answer some of the astonished comments I made yesterday, the lack of contributors to the project is baffling. So: the whole Internet relied on 10 volunteers and 1 employee and nobody helped them?
I guess this sort of comes back to one of the essential question in Free Software: how do you get the users to fund it? For some kind of software, this can be difficult; but in the case of OpenSSL I would have thought this to be an easy thing, since so many banks and web companies intensively rely on it.
But apparently, they didn’t care at all if this major piece of security they were using was able to keep up with security standards or not. Considering the number of people involved with the project, I don't see how it can put enough scrutiny and efforts to make sure it follows the best security review.
(Now, I have to wonder if the WSJ piece is actually correct in the way it counts the contributors to the project, because it's fairly possible that lots of companies making use of OpenSSL actually had security experts and developers in-house test the code and send patches and bug reports upstream; a bit like Google and that other security firm did when they found out about Heartbleed…)
According to Brett Simmons, That pretty much wraps it up for C.
The whole heartbleed bugs also reminds me that OpenSSL is also an example of bad idea when it comes to licensing issues.
The heartbleed vulnerability is not only a catastrophic security issue, it also spans other interesting topics.
The first obvious lesson, is that the communication around the vulnerability was brilliant marketing.
The other lesson, less satisfying, is why is the majority of the internet relying on a very poorly funded project?!
The Washington Post published an article that misses the real issue. The heartbleed debacle is not an issue with the fact that OpenSSL is Free Software (the Apple goto fail bug shows it’s even worse when it’s proprietary--all Apple users had to wait several days before a patch was sent), nor with the fact that the Internet have no single authority (if anything, the openssl library is a single point of failure).
I find it astonishing that OpenSSL is so poorly funded and apparently lacks a governance strategy that includes large stakeholders such as the major websites making use of the library and which, instead, are essentially all irresponsible free-riders.
The real issue here is one of responsibility.
XKCD has an amazingly simple explanation of how the vulnerability works.

Somebody working at Mozilla put together a timeline of facts surrounding Brendan Eich’s resignation.
And the real tragedy here is that Mozilla would have sorted this out satisfactorily if it hadn’t been sensationalized by the media and turned into an internet witch hunt. Anyone who wrote a news story, posted to their blog, or tweeted about Brendan without understanding paragraph (i)(c) of the Community Participation Guidelines was part of the mob that brought Brendan down.
For more than 15 years, Brendan fought for openness and freedom on the web, and led many of the people who built that open and free web. This week, in a senseless, vicious convulsion, the web turned on him.
Meanwhile, Mozilla published an FAQ.
Q: Was Brendan Eich forced out by employee pressure?
A: No. While these tweets calling for Brendan’s resignation were widely reported in the media, they came from only a tiny number of people: less than 10 of Mozilla’s employee pool of 1,000. None of the employees in question were in Brendan’s reporting chain or knew Brendan personally.
In contrast, support for Brendan’s leadership was expressed from a much larger group of employees, including those who felt disappointed by Brendan’s support of Proposition 8 but nonetheless felt he would be a good leader for Mozilla. Communication from these employees has not been covered in the media.
Which echoes something written in the timeline mentioned above:
11) On March 27th, a small number of Mozillians tweeted variants of “I am an employee of @mozilla and I’m asking @brendaneich to step down as CEO”. These tweets were reported by the tech press, and my perception is that this was the start of the media firestorm. Most (or perhaps all) of the Mozillians who tweeted this were employed by the Mozilla Foundation, not the Mozilla Corporation which means that they report to the executive director of the foundation and not to the CEO. As foundation employees, they did not share the same org chart as Brendan.
This is why pieces like this trouble me:
Both writers seem concerned that Eich's resignation is a defeat for freedom of expression. If anything, it is a victory – the ouster of a founder and CEO by his own people, at a foundation based on open and equal expression, should be the new textbook example of the system working exactly as it should.
I hope this episode is now closed and that everybody learns a lesson from this.
(Especially, the guys at Rarebit who, after publishing an article “5 reasons why Brendan Eich should step down” now write “I want to say how absolutely sad to hear that Brendan Eich stepped down.” No comments.)
The IRS says that Bitcoin is property, not a currency. Bloomberg: “It’s challenging if you have to think about capital gains before you buy a cup of coffee.” No kidding!
It's interesting, as I was discussing the relationship between property and value yesterday night with Basti.
 |
Je me baladais hier avec Basti (@skddc) qui était à Paris pour la première fois. Lorsque soudain, j'aperçus des drapeaux chinois mêlés à ceux de la république et aux armoiries de Paris ! Malheureusement, ce n'est pas aussi drôle que dans le film de Jean Yanne et son adaptation à l'opéra, Carmeng.
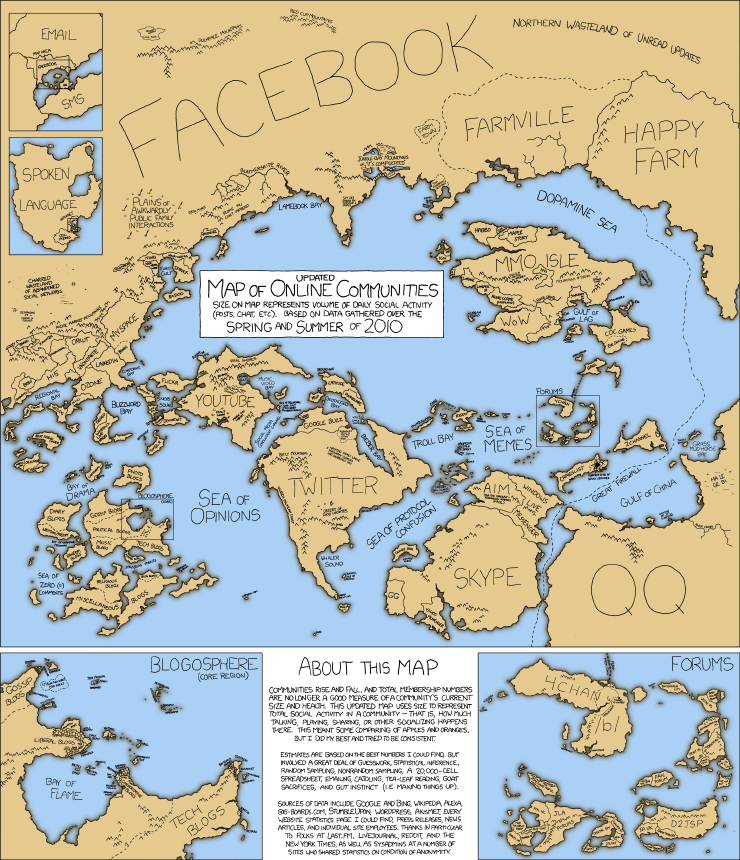
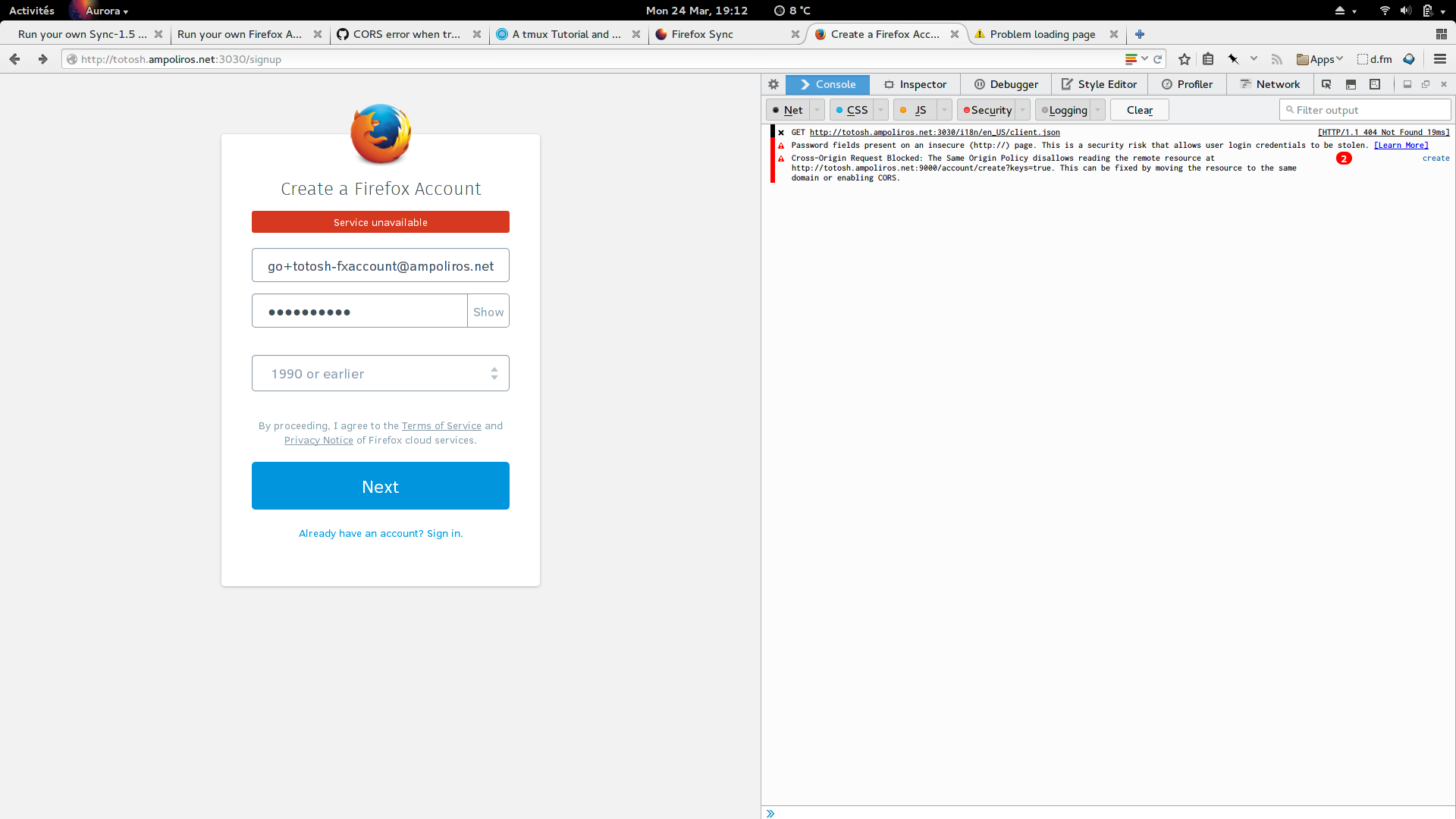
Since I first set up Firefox Sync, things have changed. Mozilla thought that they needed to completely change the user experience of setting it up in firefox, thus discarding the previous firefox sync server for a totally new system of “Firefox Accounts”.
That sounds nice, however at the moment it’s nowhere as easy to set up if you want to self-host it instead of relying on Mozilla’s services.
You have to start 3 services:
- Sync 1.5
- and the Firefox Accounts Server
Unfortunately, the READMEs are not as good as before. Sometimes, they ask you to change settings, but they don’t always tell you in which file you should modify it; or it also happens that the file they mention does not exist (e.g. the “config.json”).
I’ll have to give it another try… I hope that for next time, the documentation will have improved.
 |
I’m having a splendid Sunday at my desk, working on some moot cases for school.
Sometimes to get going, I need some good music that fits the mood. If you’re like me, you’re probably listening to some ambient or minimal music.
I’m on Trentemøller’s 2006 Last Resort right now and it feels great. I have no idea where I got that from, I just don’t remember. But anyway, thanks to the person who gave me this!

Le projet de réforme de droit d’auteur de Jean Zay dans les années 1930 est un autre de ces textes un peu oubliés, passé dans l’ombre de la loi de 1957 « sur la propriété littéraire et artistique ».
Cet intitulé malheureux est un peu comme une trahison du droit des auteurs qu’Augustin-Charles Renouard avait fondé dans son grand traité de 1838, ce traité là qui est la base de la doctrine des droits moraux en droit français.
Il est peut être temps de compiler une sélection d’articles pour donner une autre histoire du droit d’auteur en France que celle que veut parfois nous inventer certains tenants de la « propriété littéraire et artistique ».
Je rejoins complètement Calimaq dans sa conclusion :
Mais détacher le droit d’auteur de la notion de propriété, c’est aussi ouvrir la porte à un meilleur équilibre entre la protection des droits et les usages, comme le prouve ce « domaine public anticipé » chez Jean Zay. Un retour aux origines du droit d’auteur et du domaine public est difficile, mais il n’est pas complètement impossible.
BBC: Microsoft admits reading Hotmail inbox of blogger:
Microsoft is caught up in a privacy storm after it admitted it read the Hotmail inbox of a blogger while pursuing a software leak investigation.
While the search was technically legal, [Microsoft's deputy general counsel] added Microsoft would consult outside counsel in the future.
So if it’s not just legal, but “technically legal”: what does that mean?
Yes, it means the way companies like Microsoft handle privacy is wrong. Yet another example.
I just came back from the cinema, where I watched Spike Jonze’s Her. This movie has got me thinking.
One thing I notice which was funny is how Theodore’s job kind of makes him fit the same role that her, the AI, is doing for him. Let me explain a little bit. Theodore, the main character, works at beautiful-handwritten-letters.com a service where people ask him to write beautiful letters to their wife for their 50th wedding anniversary, or to their son for his diploma, etc. You get it. By writing letters for other people, expressing some of their most personal emotions for them or even, instead of them, he participates to this society where the human self dissolves.
I guess what I’m saying isn’t making sense if you haven’t seen the movie. So go see it! There aren’t movies like this every year!
Restoring an HP Touchpad webOS tablet
Here some little known, yet awesome apps or tools that I use. Thanks to the people working on these (I’m glad to have met some of them, and they’re awesome too)!
Transportr
Transportr is an Android app to help you use public transports systems. It’s simply the best one I’ve seen, and it supports a lot of systems (city-wide like Berlin or Paris and even long-distance).
Feedbin
Feedbin is an RSS web reader. It provides a pleasing reading experience and you can easily browse through items and share links. If you’re looking to host it yourself, have a look at the sources.
ikiwiki
ikiwiki powers this blog, hosted by branchable. If you like git and markdow, and editing your texts with your favourite text editor, this is for you.
Known
Known (formerly “idno”) is more “socially aware” than ikiwiki. It runs with PHP and it’s basically your easy-to-run indieweb space. If you use it with http://brid.gy you will enjoy a nice integration with twitter and other silos (see an example of my own).
YunoHost
YunoHost is custom debian distribution aiming at making self-hosting easy. It provides a nice web interface for administration of your self-hosted server and for users of the web server. If you have basic linux administration skills, this will be very helpful.
Pinboard
Pinboard a simple and efficient bookmarking app that also archives the content of marked pages (if you pay for it). Unfortunately, Pinboard is not released as free software. But you can export your bookmarks.
Sharesome
Sharesome lets you easily share files on the web. It has a pleasant interface that works well on all devices I have tested so far. It’s also available as a web app. The neat feature is that you can choose where to host your data (for instance, with remotestorage; you can get an account at https://5apps.com).
Terms of Service; Didn’t Read
Some shameless self-promo with ToSDR, the app that tells you what happens to your rights online by rating and summarising Terms of service and privacy policies. You can also get it directly in your web browser or as a web app.
If you’re looking for a curated list of awesome web services that are free of charge and based on free software and open data, look no further than Jan’s Libre projects.
Hier, j'étais au loop avec Okhin pour refaire le chiffrement de mon serveur mail, que je viens de réinstaller (Kolab 3.4, Debian 8).
Voici quelques liens qui nous ont été utiles :
How to create a self-signed SSL Certificate
Attention cependant, en suivant ces instructions on crée un certificat avec le flag CA false alors que pour utiliser un certificat autosigné sur Android, il faut absolument que le flag CA soit true (voir ci-dessous).
Finalement, voici la commande qui m'a permis de faire le certificat, dans
/etc/ssl/private/:openssl req -x509 -new -key totosh.ampoliros.net.key -out totosh.ampoliros.net.csr -days 730Cette commande remplace l'étape 2. L'étape 4 n'est donc pas nécessaire semble-t-il.
Ensuite, je copie
totosh.ampoliros.net.csrvers/etc/ssl/certs/totosh.ampoliros.net.crtpuis je configure mes services pour utiliser ce certificat ainsi que la clé privée générée à l'étape 1.-
Utilisé pour configurer Apache2.
Exemples de configuration Postfix de Benjamin Sonntag
Sans oublier de générer
dh2048.pem:openssl dhparam -out /etc/ssl/private/dh2048.pem -outform PEM -2 2048-
Utilisé pour configurer Cyrus IMAPD.
Importer un certificat autosigné dans Android
Normalement, avec la commande openssl donnée plus haut, on génère un certificat autosigné acceptable pour Android.
On peut par exemple utiliser l'application CAdroid pour importer le certificat.
Si on est root sur l'Android, on peut aussi copier le certificat
directement dans le système en passant par adb. C'est la solution
que j'ai choisie.
Installing CAcert certificates on Android as 'system' credentials without lockscreen - instructions
(En passant: j'ai un bug sur CyanogenMod qui m'enmpêche pour le moment
de modifier les paramètres de sécurité. Je suis donc passé par adb
pour autoriser l'installation de sources autres que Google avec la
commande: adb shell settings put secure install_non_market_apps 1.)
Sometimes, you want to get numbered paragraphs throughout a document.
I'm looking for a way to achieve this with pandoc, in a way that I can write once, and publish in several formats.
I added this in pandoc's LaTeX template:
$if(numberparagraphs)$
%% numerate paragraphs with a label
\newcounter{paranumero}
\newcommand{\para}[1]{%
\noindent\refstepcounter{paranumero}\llap{\small\bfseries\theparanumero\label{#1}.~}}
$endif$
That way, I can write
\para{shortId} A paragraph...
and later in the document, I can refer to that paragraph\vref{shortId}
That's good, but it only works in LaTeX. I'd like to write something similar in a Markdown document and be able to also produce HTML, or even ODT or OOXML.
I'll experiment a bit, but if you have ideas of your own... tell me :-)
TODO: allow to write \para without any value and assign it a
predictable \label... for instance the first letter of the first
five words of the paragraph.
I've been using LaTeX since about 2009.
Here's a collection of tips for Xe/La/TeX with an inclination towards use in the French language, within a legal context or in combination with ?pandoc.
LATEX
XƎTEX
<span class="latex">L<sup>A</sup>T<sub>E</sub>X</span>
<span class="xetex">X<sub>Ǝ</sub>T<sub>E</sub>X</span>
.latex sub {
vertical-align: -0.1ex;
margin-left: -0.1667em;
margin-right: -0.025em;
}
.xetex sub {
vertical-align: -0.1ex;
margin-left: -0.1667em;
margin-right: -0.125em;
}
.latex sub, .latex sup, .xetex sub {
font-size: 0.9em;
text-transform:uppercase;
}
.latex sup {
font-size: 0.85em;
vertical-align: -0.2em;
margin-left: -0.26em;
margin-right: -0.05em;
}
Edit: You should have a look at msmtp-queue-scheduler to solve this :-)
Thanks Nicolas!
I've been looking for a solution to this problem:
Sometimes, I just sent an email, and after 10 seconds I realise: “Oh, damn, I forgot to add something!” or “Oh, nooooes, I sent it to the wrong person!” Whatever. This is annoying.
Making mistakes is human. Email clients are for humans, therefore they should be able to cope with our mistakes and help fix them. That's why software should allow us to “undo” or “cancel” our actions.
Gmail does this right, so why can't we do it in Mutt too?
I wrapped my head around this a little bit. And I'm no programmer, so after trying to add some stuff here and there, I finally decided to have it with this very, very, very dirty hack. You've been warned. So here's how I do it:
I use the
msmtpqscript which allows me to queue emails when I'm offline, so thatmsmtpcan take care of sending queued email when I'm back online.I have tried to put a delay of 30 seconds any time before calling
msmtpor I tried to forcemsmtpqto queue all outgoing email for at least 30 seconds. But I couldn't make it work. So instead,I added
sleep 30 &&at the beginning of themsmtpqscript!Result: now when I send an email, I have 30 seconds to realise when I made a mistake. Then, I just need to activate plane mode on my laptop, and fix whatever needs fixing from here.
One issue with this workflow is that I can't just edit the outgoing email, I also have to make sure I update the openPGP signature. So I'd probably just delete the email and start again from Mutt.
I warned you, this is very ugly :-)
But as they say: the best way to get an answer on the net is not to ask a question, but to give the wrong answer!
So if anyone wants to implement this feature in msmtpq, that would
be great. Here's how it could work ideally, in the .muttrc:
set sendmail="msmtpq --wait 30"
set sendmail_wait=-1 #send in the background
then msmtpq could queue the email for 30 seconds before testing the
connection and feeding the email to msmtp. The Queue management
could then allow the user to pause all outgoing emails, cancel the
email containing the mistake, then sending remaining emails from the queue.
The msmtpq script is available at: http://sourceforge.net/p/msmtp/code/ci/master/tree/scripts/msmtpq/
Here’s a list of options I modified in my firefox’s about:config.
middlemouse.contentLoadURL: false
I use the mouse middle click to copy and paste stuff. So when I accidentally press that mouse middle click while reading a web page, I don’t want Firefox to load whatever’s in my buffer as a URL.
browser.urlbar.trimURLs: false
Mozilla decided to look more like Google Chrome and started to hide relevant parts of the URL like
http://. This feature has helped me exactly 0 time, while on the other hand it was annoying many times when copy/pasting from the URL bar would not give me the entire URL (and the results were not consistent).Disabling unsecure ciphers
- security.ssl3.ecdh_ecdsa_rc4_128_sha
- security.ssl3.ecdh_rsa_rc4_128_sha
- security.ssl3.ecdhe_ecdsa_rc4_128_sha
- security.ssl3.ecdhe_rsa_rc4_128_sha
- security.ssl3.rsa_rc4_128_md5 [this one seems required for Youtube's https to work]
- security.ssl3.rsa_rc4_128_sha
You can now check if your browser uses secure SSL/TLS cipher.
Replace Google with DuckDuckGo on Firefox
- browser.search.defaultenginename: DuckDuckGo
- browser.search.selectedEngine: DuckDuckGo
Other tips for Firefox:
Install the linux-xps13-archlinux kernel (now in the AUR)
Note: Since I wrote this, it’s possible that the patched kernel now has more features than only touchpad support.
Install
xf86-input-synapticsand, from AUR,toucheggandtouchegg-gce-git(this last one is to be able to configure gestures with the graphic interface).Edit
/etc/X11/xorg.conf.d/50-synaptics.confSection "InputClass" Identifier "touchpad catchall" Driver "synaptics" MatchIsTouchpad "on" Option "TapButton1" "1" Option "TapButton2" "0" Option "TapButton3" "0" Option "ClickFinger2" "0" Option "ClickFinger3" "0" # This option is recommend on all Linux systems using evdev, but cannot be # enabled by default. See the following link for details: # http://who-t.blogspot.com/2010/11/how-to-meta:ignore-configuration-errors.html MatchDevicePath "/dev/input/event*" EndSectionConfigure your gestures with Touchègg
Here's my
~/.config/touchegg/touchegg.conf:Add to your session (using
gnome-session-propertiesfor instance):touchegg
The real improvement is that I can use three-finger tapping to simulate the middle-click mouse button which is used for quick pasting or for opening links in a new tab.
As far as "pinching" is concerned, it does not work reliably at all for me.
Once you have Mutt up and running with the basic tools that will
allow you to fetch, index, view,
edit and send email, there are a couple of
things that you probably need in your .muttrc,
no matter what.
I left out all things which are about visual taste, use with external programs, etc. These are really about correcting some defaults which I think are not sane.
In Mutt, even if you are on the pager that lets you read a selected email, the
<up>and<down>keys will not help you navigate inside the email; instead they will bring you to the previous or to the next email in the index.That’s rather weird and unexpected. One of the first thing I did was trying to scroll inside an email, and Mutt suddenly browsed dozens of emails from the index (even marking them as read…). That’s quite unhelpful. To solve this, add:
bind pager <up> previous-line #scroll inside the message rather than the index bind pager <down> next-lineThat way, you can scroll, or use the arrow keys to read an email inside the pager.
When the pager is not opened, the up and down keys will behave as usual in the index.
To make Mutt faster
set sleep_time = 0 # be fastDon’t worry, this does not affect anything, it will just be faster. Here’s the doc about
sleep_time:Specifies time, in seconds, to pause while displaying certain informational messages, while moving from folder to folder and after expunging messages from the current folder. The default is to pause one second, so a value of zero for this option suppresses the pause.
When you display email in the pager, it can look ugly when the lines are too long and that Mutt, by default, is not very nice about line-wrapping because it can cut words in the middle. You probably want to add:
set smart_wrapChanging between mailboxes can be a pain by default in Mutt. You need to tell Mutt where to find your several mailboxes, so you’ll be able to switch between them more easily (for instance by pressing
yor with the sidebar). Add:mailboxes $MailI have seen on some Mutt configs that
ysometimes does not toggle the list of mailboxes. In that case, you can add something like:macro index y "<change-folder>?<toggle-mailboxes>" "show incoming mailboxes list"
The way it works is:
- You’re reading an email on Mutt and you think: Oh, I should really remember that because I need to do X.
- You pass this email to emacs’ org-mode containing:
- the subject, the date and the from
- a link to that email which is
mutt:Message-ID
- You add some information if you wish to, and you save this in your org-mode todo file.
Now, you’re in your org-mode todo list, you can work with it as usual. Now you have this bit, and you need to remember what it’s about exactly. You can click the link in org-mode, and it will open Mutt and show you the right email in Mutt!
- More info on Zack’s blog
- Get org-mutt directly from his git repo
Make mutt-open work with mutt-sidebar
I used mutt-sidebar and I couldn’t get ./mutt-open to work
correctly. I fixed this by changing:
HIDE_SIDEBAR_CMD="B" # set to empty string if sidebar is not used
You need to update B with whatever you use to toggle the
sidebar. I use CTRL-B so I changed it to
HIDE_SIDEBAR_CMD="\CB". That’s it!
This is the due to the fact that mutt-open has
something called mutt_keys that’s used to display the right
email in mutt. However in its current state mutt_keys decides to
toggle the sidebar before it actually shows the email. Hence if
the toggle sidebar key is not well defined in mutt-open, mutt will
hang up there. So I changed this to:
mutt_keys="/=i$msgid\n\n$HIDE_SIDEBAR_CMD"
Make mutt-open work with mutt-kz
Since mutt-kz comes with a sidebar as well, the previous paragraph applies. But you might need further changes to the original mutt-open script. Here’s how mine works:
mutt_keys="<vfolder-from-query>id:$msgid\n\n<entire-thread>"
This should work with any carddav server, but if you use Kolab's carddav server here's some extra tip!
The problem you want to fix is: it's impossible to remember everyone's email address. This problem is solved by most email programs because they are linked to a contact list already. However, for those of us using Mutt, there's no full contact integration so you need to rely on something else.
One obvious solution is to rely on a mail indexer to search and find addresses in emails from the past. If you use mu, here's how Karsten does it.
However, that's not really helping if you have contact information from multiple sources (e.g. typing on your mobile the email address of somebody you just met AFK). This is where a contact server is handy.
If you use Google's contacts, you can use goobook it works well but it's quite slow IMHO. And obviously, the problem is that you have given up your whole contact list to Google.
Find your Kolab addressbook
With Kolab 3.1 comes a CardDav/CalDav/webDav server! Version 3.1 was just released today. So let's use that instead.
When I set up Kolab 3.1 before the official release, I got a packaging bug in CentOS, but it's easy to fix.
The *Dav server is located at https://kolab.example.org/iRony. Now, you need to find how to link to a specific addressbook. I tried to have a look at the Roundcube interface, for a folder id or something, but I could not find any that was working.
Just connect a webDav client (in Nautilus, File > Connect to a server) to the iRony folder, and then just navigate to find the addressbook identifier (look in the address bar!)
Hopefully, this will soon not be needed any longer. There will be a "Show address book URL" setting directly in Roundcube's contacts menu.
Sync your CardDav addressbook with pyCardDAV
Now install pyCardDav which just landed on Debian last month:
# apt-get install pycarddavSync pycarddav after you entered the Kolab addressbook resource in the config file with
pycardsyncerI advise you run this with
--debugto make sure that it does not get stuck in case you have some illegal characters inside one of your vCards. If it gets stuck, then you can just go back to your webDav client and edit the file that's causing trouble.If all goes well, you should be able to search for contacts inside your local copy:
% pc_query hugo searching for hugo... Name: Hugo Roy TEL (CELL): +... EMAIL (INTERNET\, WORK): hugo at fsfe dot org
Lookup directly from Mutt
I just added this to my ~/.muttrc:
set query_command="pc_query -m '%s'"
bind editor <Tab> complete-query
That way, in Mutt, just type ‘Q’ to search for a contact. Or you can also press ‘m’ to start a new message, start typing in the ‘To:’ field the name of your contact and just press [Tab] to have autocompletion!
Hey, did you know that on Mutt, ‘CTRL’+K will import public openPGP keys attached to emails (with the right MIME type)?
That makes signing and sharing keys even easier ☺
Thanks gollo for the tip!
I began using Mutt in March 2013. (I was using Gnome's Evolution before, but its searches were really slow and one day I really freaked out when Evolution did something weird which led me to believe that I couldn't see my emails since 2010. It turns out everything was fine, but Evolution hang up on me).
Beginning on Mutt is “not easy.” I went to Mutterwares to have experienced user show me how they use it. You might be interested in some of the information collected there.
First tips for Mutt beginners
Once you have Mutt up and running with the basic tools that will
allow you to fetch, index, view,
edit and send email, there are a couple of
things that you probably need in your .muttrc,
no matter what.
I left out all things which are about visual taste, use with external programs, etc. These are really about correcting some defaults which I think are not sane.
In Mutt, even if you are on the pager that lets you read a selected email, the
<up>and<down>keys will not help you navigate inside the email; instead they will bring you to the previous or to the next email in the index.That’s rather weird and unexpected. One of the first thing I did was trying to scroll inside an email, and Mutt suddenly browsed dozens of emails from the index (even marking them as read…). That’s quite unhelpful. To solve this, add:
bind pager <up> previous-line #scroll inside the message rather than the index bind pager <down> next-lineThat way, you can scroll, or use the arrow keys to read an email inside the pager.
When the pager is not opened, the up and down keys will behave as usual in the index.
To make Mutt faster
set sleep_time = 0 # be fastDon’t worry, this does not affect anything, it will just be faster. Here’s the doc about
sleep_time:Specifies time, in seconds, to pause while displaying certain informational messages, while moving from folder to folder and after expunging messages from the current folder. The default is to pause one second, so a value of zero for this option suppresses the pause.
When you display email in the pager, it can look ugly when the lines are too long and that Mutt, by default, is not very nice about line-wrapping because it can cut words in the middle. You probably want to add:
set smart_wrapChanging between mailboxes can be a pain by default in Mutt. You need to tell Mutt where to find your several mailboxes, so you’ll be able to switch between them more easily (for instance by pressing
yor with the sidebar). Add:mailboxes $MailI have seen on some Mutt configs that
ysometimes does not toggle the list of mailboxes. In that case, you can add something like:macro index y "<change-folder>?<toggle-mailboxes>" "show incoming mailboxes list"
Here is a list of mutt tips. My ~/.mutt is public.
I’m a new ikiwiki user. I’ve been interested in using this, because of the git version control, and I liked the idea that I could just clone the entire ikiwiki on my laptop and thus edit it offline with my favourite editor.
So, as every new user, I make some mistakes which could have been pretty easily avoided. Here’s one quite significant.
In order to generate the ?timeline I use the aggregate plugin. That way I can pull content from lots of sources through feeds, and put it into one page and one feed. This timeline is like a big feed of things I do everywhere on the web. In a way, it’s a PESOS approach in the IndieWeb.
One important technical detail is that the directive displays information on the page itself, such as when was the last time the source feed was checked. This means that each time the feeds are checked, the page that contains the directive has to rebuild in order to update the information.
Obviously, it was a very bad idea for the timeline, because that meant that each time the sources were checked, the whole timeline has to rebuild whole over again. And it took CPU time.
The people running http://branchable.com fixed it for me. Thanks to them! I’ll make sure to use it as a reminder and have separate files for that in the future!
If you have other tips to make ikiwiki more efficient, please comment!
It’s quite annoying when you click somebody's name or email on a web page and that Firefox cannot figure out how to rely on your system preferences to send an email.
For instance, my system is set up so that when I click on an email address or mailto: link anywhere, gnome-terminal opens up with Mutt ready to send an email. For some reason, Firefox tries to figure out all by itself which program I should use.
I have tried to make Firefox use gnome-terminal with Mutt, but it
didn’t work. However, it's possible to add your own webmail there
(for some reason, I could choose between Yahoo Mail, Gmail and
Mykolab.com but I can't remember how I did that). Now that I have
my own Kolab instance with roundcube, I decided to add my own
webmail there. Unfortunately, it seems there's no way from the
graphical interface, so I went straight to:
~/.mozilla/firefox/iceweaselprofile.hugo/mimeTypes.rdf.
It's quite a big file FWIW (885 lines here). I did not have a look at the details, but hopefully just adding this helps (for the second block, make sure to merge with existing mailto handlers):
<RDF:Description RDF:about="urn:handler:web:https://kolab.example.org/roundcubemail/?_task=mail&_action=compose&_to=%s"
NC:prettyName="Kolab Groupware"
NC:uriTemplate="https://kolab.example.org/roundcubemail/?_task=mail&_action=compose&_to=%s" />
<RDF:Description RDF:about="urn:scheme:handler:mailto"
NC:alwaysAsk="true">
<NC:possibleApplication
RDF:resource="urn:handler:web:https://kolab.example.org/roundcubemail/?_task=mail&_action=compose&_to=%s"/>
</RDF:Description>
(Just replace https://kolab.example.org/roundcubemail/ with your own Roundcube location. And of course, if you don't use Kolab replace "Kolab Groupware" by whatever.)
When you get used to a text editor that you like, you start to get annoyed by all the times you have to enter some text and you're using a shitty editor. This is so true on the web when you try to write something in more than 140 characters.
Matthias showed me a nice firefox extension: “it's all text” (you can also install it from debian repos). For each text box, you just click a small “edit” button and it will fire up vim[^1] and let you edit the text there, then send it back to the web interface.
[^1]: Actually, I had to configure it to start GVim instead of vim. I suppose there's a way to launch a terminal and then vim…
Reply to an email, easily delete the parts below line
When I reply to emails, Mutt fires up vim. Then I can quickly navigate until I reach the parts I want to reply to specifically. Sometimes it’s just a portion of the whole email, so I want to leave out the rest. Matthias shared a nice tip that allowed him to do that quickly.
Unfortunately, it wasn’t working properly for me. I figured out it’s because in markdown mode, I use folding. By default, my own signature is folded. So I modified the rule a little bit, and here it goes, just add in your ~/.vimrc:
So when you're below the part you’re replying to, just press
,dd and it will delete the rest of the email between
the line and your signature.
It only works if your signature is well delimited by --
and if folding is on. If you do not use folding, then use
the original config provided by
Matthias:
noremap ,dd :.;/^-- $/dO--
I began using vim in January 2013. (I was mostly using gedit before, but it was so slow at times that it couldn’t keep up with me typing on the keyboard.) I suppose my use of vim isn’t the most widespread. I write code occasionally only, I mainly write emails and documents, so my set-up reflects this and the tips I share here are not the most interesting for coders.
Here is a full list of vim tips. My beginner’s ~/.vim is public.
« Il est difficile de dire la vérité, car il n’y en a qu’une, mais elle est vivante, et a par conséquent un visage changeant. »
Franz Kafka,
cité par Étienne Klein, Le goût du vrai (2020)
Most of the hardware devices are, even as you read this, available as off-the-shelf items, just waiting to be plugged into each other in order to put an end to the record business as we know it.
Frank Zappa with Peter Occhiogrosso, The Real Frank Zappa Book (p. 336, Chapter 18, “Failure”), A Touchstone Book, published by Simon & Schuster, 1988-1989. Also see, “A proposal for a system to replace phonograph record merchandising”.
– Bah, la vérité, la vérité… Qui peut dire ce qui est vrai et ce qui ne l'est pas, commandant ! Pour nous, l'essentiel, ce n'est pas la vérité, c'est la justice, non ?
Pierre Lemaitre, Alex (2011)
Il est juste que ce qui est juste soit suivi ; il est nécessaire que ce qui est fort soit suivi. La justice sans la force est impuissante, la force sans la justice est tyrannique. La justice sans force est contredite, parce qu'il y a toujours des méchants ; la force sans la justice est accusée. Il faut donc mettre ensemble la justice et la force et pour cela faire en sorte que ce qui est juste soit fort, ou que ce qui est fort soit juste.
La justice est sujette à dispute, la force est très reconnaissable et sans dispute. Ainsi on n'a pu donner la force à la justice, parce que la force a contredit la justice et a dit qu'elle était injuste, et a dit que c'était elle qui était juste. Et ainsi ne pouvant faire que ce qui est juste fût fort, on a fait que ce qui est fort fût juste…
Ne pouvant faire qu'il soit forcé d'obéir à la justice, on a fait qu'il soit juste d'obéir à la force. Ne pouvant fortifier la justice, on a justifié la force, afin que le juste et le fort fussent ensemble, et que la paix fût, qui est le souverain bien.
Pascal, Pensées (à vérifier)
Information is not knowledge. Knowledge is not wisdom. Wisdom is not truth. Truth is not beauty. Beauty is not love. Love is not music. Music is the best…
Frank Zappa, “Packard Goose”, Joe’s Garage Act III (1979)
„Nein,“ sagte der Geistliche, „man muß nicht alles für wahr halten, man muß es nur für notwendig halten.“ „Trübselige Meinung,“ sagte K. „Die Lüge wird zur Weltordnung gemacht.“
Non, dit le prêtre, on n’a pas à tenir tout pour vrai, on a seulement à le tenir pour nécessaire.
— Triste opinion, dit K. ; c’est le mensonge érigé en loi de l’univers.
Franz Kafka, Le Procès, Dans la Cathédrale (1925)
It's easier to move without a piano.
Michiel B. de Jong in Berlin, Kreuzberg (2012)
God, grant me the serenity to accept the things I cannot change,
courage to change the things I can,
and wisdom to know the difference.Que Dieu
m'accorde la sérénité
d'accepter les choses que je ne peux pas changer,
le courage de transformer celles qui s'y prêtent
et la sagesse
de savoir toujours les distinguer.Billy Pilgrim, in Slaughterhouse-Five, or The Children's Crusade: A Duty-Dance with Death (1969)
With great power comes great responsibility.
Uncle Ben in Spider-Man (2002)
Toute Société dans laquelle la garantie des Droits n’est pas assurée, ni la séparation des Pouvoirs déterminée, n’a point de Constitution.
Article ⅩⅥ de la Déclaration des droits de l'homme et du citoyen du 26 août 1789 (inspiré de Montesquieu)
Violence is the last refuge of the incompetent.
La violence est le dernier refuge de l'incompétence
Salvador Hardin, in Isaac Asimov's Foundation (1951)
Without deviation from the norm, progress is not possible.
Frank Zappa (1940-1993) video
Dans la pratique — les révolutionnaires se trompent toujours, parce qu’ils croient toujours la vérité trop simple, ont trop confiance en eux-mêmes et s’imaginent qu’ils ont trouvé et déterminé le terme du progrès humain ; tandis que le propre du progrès, c’est de n’avoir pas de terme, de n’atteindre ceux qu’on lui propose qu’en les transformant, de ne résoudre les problèmes qu’en en changeant les données.
In practical matters the revolutionary spirits always make mistakes, because they always believe truth to be too simple, because they are too confident of themselves, and imagine that they have found and fixed the end and aim of human progress. Whereas real progress is to have no end; is to reach those ends which one has put before one’s self, only to transform them; to solve problems only by changing their data.
Jean-Marie Guyau, Esquisse d’une morale sans obligation ni sanction, « Le risque métaphysique dans la spéculation », 1885
Si vous êtes arrivé jusqu’ici, vous devriez consulter les archives.